MNIST Addition
For detailed code implementation, please view it on GitHub.
Below shows an implementation of MNIST Addition. In this task, pairs of MNIST handwritten images and their sums are given, along with a domain knowledge base containing information on how to perform addition operations. The task is to recognize the digits of handwritten images and accurately determine their sum.
Intuitively, we first use a machine learning model (learning part) to convert the input images to digits (we call them pseudo-labels), and then use the knowledge base (reasoning part) to calculate the sum of these digits. Since we do not have ground-truth of the digits, in Abductive Learning, the reasoning part will leverage domain knowledge and revise the initial digits yielded by the learning part through abductive reasoning. This process enables us to further update the machine learning model.
# Import necessary libraries and modules
import os.path as osp
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.optim import RMSprop, lr_scheduler
from ablkit.bridge import SimpleBridge
from ablkit.data.evaluation import ReasoningMetric, SymbolAccuracy
from ablkit.learning import ABLModel, BasicNN
from ablkit.reasoning import KBBase, Reasoner
from ablkit.utils import ABLLogger, print_log
from datasets import get_dataset
from models.nn import LeNet5
Working with Data
First, we get the training and testing datasets:
train_data = get_dataset(train=True, get_pseudo_label=True)
test_data = get_dataset(train=False, get_pseudo_label=True)
train_data and test_data share identical structures:
tuples with three components: X (list where each element is a
list of two images), gt_pseudo_label (list where each element
is a list of two digits, i.e., pseudo-labels) and Y (list where
each element is the sum of the two digits). The length and structures
of datasets are illustrated as follows.
Note
gt_pseudo_label is only used to evaluate the performance of
the learning part but not to train the model.
print(f"Both train_data and test_data consist of 3 components: X, gt_pseudo_label, Y")
print("\n")
train_X, train_gt_pseudo_label, train_Y = train_data
print(f"Length of X, gt_pseudo_label, Y in train_data: " +
f"{len(train_X)}, {len(train_gt_pseudo_label)}, {len(train_Y)}")
test_X, test_gt_pseudo_label, test_Y = test_data
print(f"Length of X, gt_pseudo_label, Y in test_data: " +
f"{len(test_X)}, {len(test_gt_pseudo_label)}, {len(test_Y)}")
print("\n")
X_0, gt_pseudo_label_0, Y_0 = train_X[0], train_gt_pseudo_label[0], train_Y[0]
print(f"X is a {type(train_X).__name__}, " +
f"with each element being a {type(X_0).__name__} " +
f"of {len(X_0)} {type(X_0[0]).__name__}.")
print(f"gt_pseudo_label is a {type(train_gt_pseudo_label).__name__}, " +
f"with each element being a {type(gt_pseudo_label_0).__name__} " +
f"of {len(gt_pseudo_label_0)} {type(gt_pseudo_label_0[0]).__name__}.")
print(f"Y is a {type(train_Y).__name__}, " +
f"with each element being an {type(Y_0).__name__}.")
- Out:
Both train_data and test_data consist of 3 components: X, gt_pseudo_label, Y Length of X, gt_pseudo_label, Y in train_data: 30000, 30000, 30000 Length of X, gt_pseudo_label, Y in test_data: 5000, 5000, 5000 X is a list, with each element being a list of 2 Tensor. gt_pseudo_label is a list, with each element being a list of 2 int. Y is a list, with each element being an int.
The ith element of X, gt_pseudo_label, and Y together constitute the ith data example. As an illustration, in the first data example of the training set, we have:
X_0, gt_pseudo_label_0, Y_0 = train_X[0], train_gt_pseudo_label[0], train_Y[0]
print(f"X in the first data example (a list of two images):")
plt.subplot(1,2,1)
plt.axis('off')
plt.imshow(X_0[0].squeeze(), cmap='gray')
plt.subplot(1,2,2)
plt.axis('off')
plt.imshow(X_0[1].squeeze(), cmap='gray')
plt.show()
print(f"gt_pseudo_label in the first data example (a list of two ground truth pseudo-labels): {gt_pseudo_label_0}")
print(f"Y in the first data example (their sum result): {Y_0}")
- Out:
X in the first data example (a list of two images):
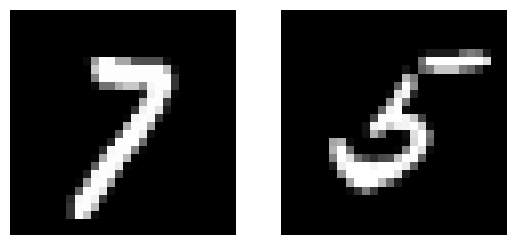
gt_pseudo_label in the first data example (a list of two ground truth pseudo-labels): [7, 5] Y in the first data example (their sum result): 12
Building the Learning Part
To build the learning part, we need to first build a machine learning
base model. We use a simple LeNet-5 neural
network, and encapsulate it
within a BasicNN object to create the base model. BasicNN is a
class that encapsulates a PyTorch model, transforming it into a base
model with a sklearn-style interface.
net = LeNet5(num_classes=10)
loss_fn = nn.CrossEntropyLoss(label_smoothing=0.1)
optimizer = RMSprop(net.parameters(), lr=0.001, alpha=0.9)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
scheduler = lr_scheduler.OneCycleLR(optimizer, max_lr=0.001, pct_start=0.1, total_steps=100)
base_model = BasicNN(
net,
loss_fn,
optimizer,
scheduler=scheduler,
device=device,
batch_size=32,
num_epochs=1,
)
BasicNN offers methods like predict and predict_proba, which
are used to predict the class index and the probabilities of each class
for images. As shown below:
data_instances = [torch.randn(1, 28, 28) for _ in range(32)]
pred_idx = base_model.predict(X=data_instances)
print(f"Predicted class index for a batch of 32 instances: np.ndarray with shape {pred_idx.shape}")
pred_prob = base_model.predict_proba(X=data_instances)
print(f"Predicted class probabilities for a batch of 32 instances: np.ndarray with shape {pred_prob.shape}")
- Out:
Predicted class index for a batch of 32 instances: np.ndarray with shape (32,) Predicted class probabilities for a batch of 32 instances: np.ndarray with shape (32, 10)
However, the base model built above deals with instance-level data
(i.e., individual images), and can not directly deal with example-level
data (i.e., a pair of images). Therefore, we wrap the base model into
ABLModel, which enables the learning part to train, test, and
predict on example-level data.
model = ABLModel(base_model)
As an illustration, consider this example of training on example-level
data using the predict method in ABLModel. In this process, the
method accepts data examples as input and outputs the class labels and
the probabilities of each class for all instances within these data
examples.
from ablkit.data.structures import ListData
# ListData is a data structure provided by ABLkit that can be used to organize data examples
data_examples = ListData()
# We use the first 100 data examples in the training set as an illustration
data_examples.X = train_X[:100]
data_examples.gt_pseudo_label = train_gt_pseudo_label[:100]
data_examples.Y = train_Y[:100]
# Perform prediction on the 100 data examples
pred_label, pred_prob = model.predict(data_examples)['label'], model.predict(data_examples)['prob']
print(f"Predicted class labels for the 100 data examples: \n" +
f"a list of length {len(pred_label)}, and each element is " +
f"a {type(pred_label[0]).__name__} of shape {pred_label[0].shape}.\n")
print(f"Predicted class probabilities for the 100 data examples: \n" +
f"a list of length {len(pred_prob)}, and each element is " +
f"a {type(pred_prob[0]).__name__} of shape {pred_prob[0].shape}.")
- Out:
Predicted class labels for the 100 data examples: a list of length 100, and each element is a ndarray of shape (2,). Predicted class probabilities for the 100 data examples: a list of length 100, and each element is a ndarray of shape (2, 10).
Building the Reasoning Part
In the reasoning part, we first build a knowledge base which contains
information on how to perform addition operations. We build it by
creating a subclass of KBBase. In the derived subclass, we
initialize the pseudo_label_list parameter specifying list of
possible pseudo-labels, and override the logic_forward function
defining how to perform (deductive) reasoning.
class AddKB(KBBase):
def __init__(self, pseudo_label_list=list(range(10))):
super().__init__(pseudo_label_list)
# Implement the deduction function
def logic_forward(self, nums):
return sum(nums)
kb = AddKB()
The knowledge base can perform logical reasoning (both deductive reasoning and abductive reasoning). Below is an example of performing (deductive) reasoning, and users can refer to Performing abductive reasoning in the knowledge base for details of abductive reasoning.
pseudo_labels = [1, 2]
reasoning_result = kb.logic_forward(pseudo_labels)
print(f"Reasoning result of pseudo-labels {pseudo_labels} is {reasoning_result}.")
- Out:
Reasoning result of pseudo-labels [1, 2] is 3.
Note
In addition to building a knowledge base based on KBBase, we
can also establish a knowledge base with a ground KB using GroundKB,
or a knowledge base implemented based on Prolog files using
PrologKB. The corresponding code for these implementations can be
found in the main.py file. Those interested are encouraged to
examine it for further insights.
Then, we create a reasoner by instantiating the class Reasoner. Due
to the indeterminism of abductive reasoning, there could be multiple
candidates compatible with the knowledge base. When this happens, reasoner
can minimize inconsistencies between the knowledge base and
pseudo-labels predicted by the learning part, and then return only one
candidate that has the highest consistency.
reasoner = Reasoner(kb)
Note
During creating reasoner, the definition of “consistency” can be
customized within the dist_func parameter. In the code above, we
employ a consistency measurement based on confidence, which calculates
the consistency between the data example and candidates based on the
confidence derived from the predicted probability. In
examples/mnist_add/main.py, the --dist-func flag lets you swap in
other predefined options (hamming, avg_confidence, similarity,
rejection) without editing the code.
Also, during the process of inconsistency minimization, we can leverage
ZOOpt library for acceleration.
Options for this are also available in examples/mnist_add/main.py. Those interested are
encouraged to explore these features.
Building Evaluation Metrics
Next, we set up evaluation metrics. These metrics will be used to
evaluate the model performance during training and testing.
Specifically, we use SymbolAccuracy and ReasoningMetric, which are
used to evaluate the accuracy of the machine learning model’s
predictions and the accuracy of the final reasoning results,
respectively.
metric_list = [SymbolAccuracy(prefix="mnist_add"), ReasoningMetric(kb=kb, prefix="mnist_add")]
Bridging Learning and Reasoning
Now, the last step is to bridge the learning and reasoning part. We
proceed with this step by creating an instance of SimpleBridge.
bridge = SimpleBridge(model, reasoner, metric_list)
Perform training and testing by invoking the train and test
methods of SimpleBridge.
# Build logger
print_log("Abductive Learning on the MNIST Addition example.", logger="current")
log_dir = ABLLogger.get_current_instance().log_dir
weights_dir = osp.join(log_dir, "weights")
bridge.train(train_data, loops=1, segment_size=0.01, save_interval=1, save_dir=weights_dir)
bridge.test(test_data)
The log will appear similar to the following:
- Log:
abl - INFO - Abductive Learning on the MNIST Addition example. abl - INFO - Working with Data. abl - INFO - Building the Learning Part. abl - INFO - Building the Reasoning Part. abl - INFO - Building Evaluation Metrics. abl - INFO - Bridge Learning and Reasoning. abl - INFO - loop(train) [1/2] segment(train) [1/100] abl - INFO - model loss: 2.25980 abl - INFO - loop(train) [1/2] segment(train) [2/100] abl - INFO - model loss: 2.14168 abl - INFO - loop(train) [1/2] segment(train) [3/100] abl - INFO - model loss: 2.02010 ... abl - INFO - loop(train) [2/2] segment(train) [1/100] abl - INFO - model loss: 0.90260 ... abl - INFO - Eval start: loop(val) [2] abl - INFO - Evaluation ended, mnist_add/character_accuracy: 0.993 mnist_add/reasoning_accuracy: 0.986 abl - INFO - Test start: abl - INFO - Evaluation ended, mnist_add/character_accuracy: 0.991 mnist_add/reasoning_accuracy: 0.980
Command-line options
In addition to the standard pipeline above, examples/mnist_add/main.py accepts
several flags that switch in alternative methods. The defaults reproduce the
standard pipeline, so existing usage is unaffected.
--method {standard,a3bl,verification}: choose the learning/reasoning pipeline.standardusesReasoner/SimpleBridge.a3bluses the ambiguity-awareA3BLReasonertogether withA3BLBridge.verificationusesVerificationReasonerandVerificationBridge: rather than picking one best candidate bydist_func, it enumerates the top--top-kconsistent candidates by joint probability and trains the model once per candidate. All methods share the sameBasicNN/ABLModelwrappers.--dist-func {hamming,confidence,avg_confidence,similarity,rejection}: passed straight to the reasoner.similarityrequires the wrapped PyTorch model to implementextract_features(x)(theLeNet5in this example does);BasicNNthen surfaces those embeddings to the reasoner automatically. Ignored when--method verification.--labeled-ratio FLOAT: fraction in(0, 1]of training samples that keep their ground-truth pseudo-labels. Values below1.0enable the semi-supervised pipeline (use_supervised_data=Trueonbridge.train). Only valid with--method standard.--top-k INT: number of consistent candidates the verification reasoner enumerates per example. Only used with--method verification. Defaults to1.
Examples:
# Standard pipeline (default)
python main.py
# A3BL with similarity-based consistency
python main.py --method a3bl --dist-func similarity
# Semi-supervised: keep 30% of pseudo-labels, abduce the rest
python main.py --labeled-ratio 0.3
# Rejection-aware reasoning
python main.py --dist-func rejection
# Verification Learning: train on the top-3 consistent candidates
python main.py --method verification --top-k 3
Environment
For all experiments, we used a single linux server. Details on the specifications are listed in the table below.
| CPU | GPU | Memory | OS |
|---|---|---|---|
| 2 * Xeon Platinum 8358, 32 Cores, 2.6 GHz Base Frequency | A100 80GB | 512GB | Ubuntu 20.04 |
Performance
We present the results of ABL as follows, which include the reasoning accuracy (the proportion of equations that are correctly summed), and the training time used to achieve this accuracy. These results are compared with the following methods:
NeurASP: An extension of answer set programs by treating the neural network output as the probability distribution over atomic facts;
DeepProbLog: An extension of ProbLog by introducing neural predicates in Probabilistic Logic Programming;
LTN: A neural-symbolic framework that uses differentiable first-order logic language to incorporate data and logic;
DeepStochLog: A neural-symbolic framework based on stochastic logic program.
| Method | Accuracy | Time to achieve the Acc. (s) | Average Memory Usage (MB) |
|---|---|---|---|
| NeurASP | 96.2 | 966 | 3552 |
| DeepProbLog | 97.1 | 2045 | 3521 |
| LTN | 97.4 | 251 | 3860 |
| DeepStochLog | 97.5 | 257 | 3545 |
| ABL | 98.1 | 47 | 2482 |